How to organise your scanned documents? The shocking truth: file names do not matter!
Getting your documents scanned and digitised is an excellent first step, so well done! However, as more files accumulate, the question arises: how can you best organise them?

Getting your documents scanned and digitised is an excellent first step, so well done! However, as more files accumulate, the question arises: how can you best organise them? Before diving into the specifics of file naming, organisation, and the tools available—which I will cover in this post—let's take a moment to consider the broader context.
Browse or search
For decades, there have been only two primary methods, or paradigms, for locating files in the digital realm. You can either search for them using a search term or query, or you can browse for them using a pre-built folder structure or by creating your own.
Everything in this space has been built around these two concepts, regardless of the operating system you use, be it Windows, Linux, or macOS. They all offer search functionality and a file system for browsing.
Even the web adopted this concept, providing search engines on one hand and directories, which resemble hierarchical menu structures, on the other. Whenever you encounter a menu on the web, it's a type of browsing experience.
These two methods have been the standard.
Until today
However, this is a topic for another blog post. I mention it because understanding these methods becomes crucial when organising your files for the future.
I believe a third method is emerging with the advent of AI. This involves what is now known as prompt engineering, which can be seen as an advanced form of search. By crafting a sophisticated search term, or prompt, AI can search through your documents—provided it has been allowed to learn from them—and return relevant results.
There's another emerging aspect that is becoming increasingly important, one that has never been fully realised before—either because it wasn't feasible or affordable for the average user.
This is the summarisation of documents. Imagine a future where you no longer need to search or browse manually. Instead, you simply ask your AI assistant for information, and it retrieves the data for you. This could become the third method, alongside searching and browsing, for finding your information and files as you build a digitized document base. However, that's a topic for another post.
Let's return to the present reality.
I embarked on my journey to go paperless in 2018. After digitising over 3,000 files and accumulating several gigabytes of data, I've learned some surprising truths.
Initially, I was a strong advocate for embedding as much detail—what we call metadata—into file names as possible to make them easier to find. However, as we all lead increasingly busy lives, I've changed my approach.
File names no longer matter
Over the years, I've come to a conclusion that might be controversial: while many may argue that file names are important, I've realised that they no longer matter as much as they once did. This might be a shocking truth for some, but it's a realisation that has shaped how I manage my digital files today.
So, how do I name my files in my digital life?
The answer is simple: they are autogenerated. You might see some examples below:
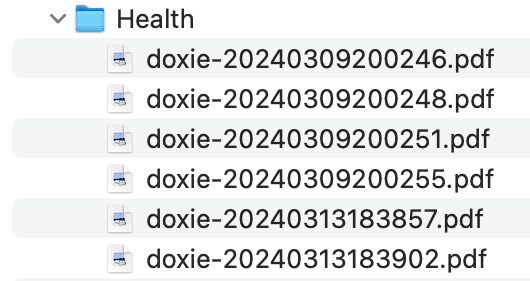
Even the first part of the file name doesn't really matter. When you see "doxie," it's just the name of the companion software tool for my document scanner. This software automatically attaches this prefix to every file name. The rest of the file name is an autogenerated timestamp, which includes the date and time when I scanned the document.
But, will I remember the exact date and time I scanned a file when I'm searching for it?
No, it doesn't matter because what truly matters is the data inside the file. In the past, naming files was a manual process, where I tried to include as many details and metadata as possible. But today, with 3,000 files and counting, I don't have the time or memory to recall when each file was scanned. The only essential criterion for file names now is that each one must be unique. I achieve this by using an autogenerated timestamp.
Let's move on. Imagine I have over 3,000 files with these timestamps. I dedicate no more than 20 minutes a week to catching up on paperwork, digitising, and scanning these files. Within those 20 minutes, I focus on sorting them efficiently.
Flat hierarchical folder structure
In addition to using autogenerated file names, I've developed a very flat folder hierarchy that I build as I go. There's an important lesson here: you won't get it perfect the first time. As you scan more documents, you'll realise that some might belong in different categories, prompting you to create new folders.
By "flat hierarchy," I mean I try not to go deeper than three levels: a top level, a middle level, and, if absolutely necessary, a third level. You can see an example below, but your approach may vary.
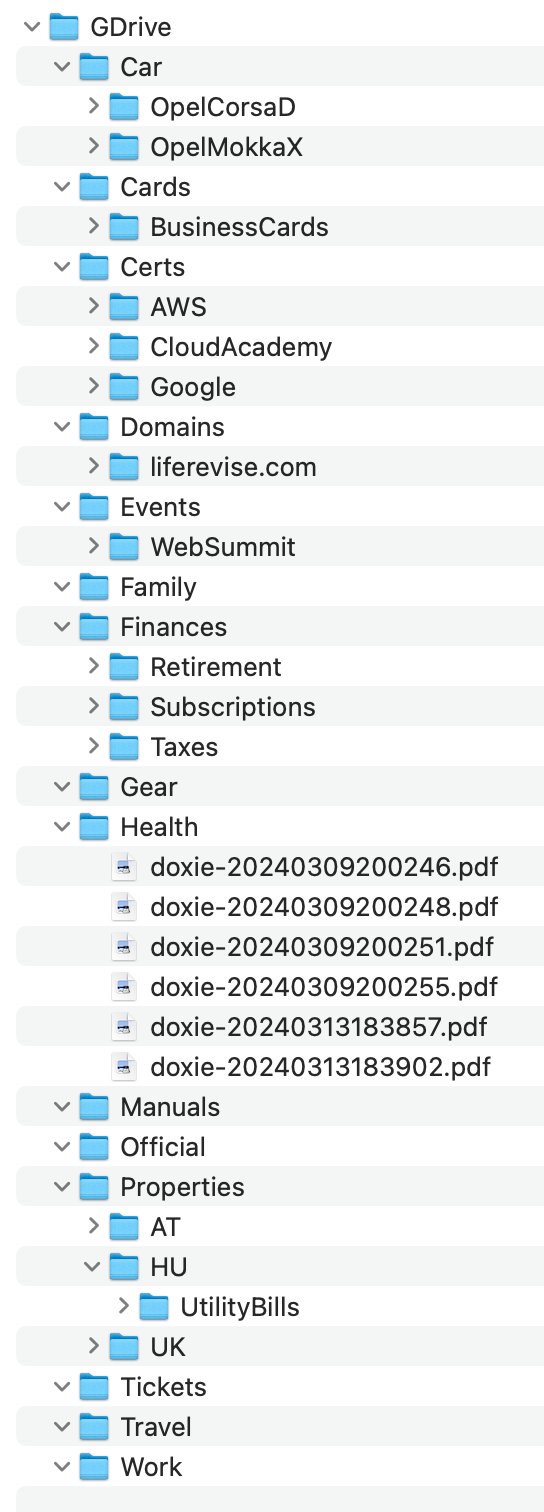
This method helps me organise my files and makes it easier to browse through categories and quickly find what I need among just a few files.
I use two main methods to search for files: browsing through my folder structure and utilising full-text search capabilities, like those offered by Google Drive. I store all my documents in the cloud with Google Drive and back them up separately. Google Drive provides full-text search within files and supports the hierarchical structure I've built over the years.
Special tools
There are also specialised tools available, such as Paperless and its next-generation version, Paperless NG. These tools can be downloaded and installed if you prefer to host your document management system yourself, without relying on cloud providers like Google.
To summarise, here are the key takeaways from my experience:
First, file names don't matter as much as they used to.
Second, try to build a flat hierarchy for organising your files. Spend just 20 minutes a week sorting and digitising, and it will make your life easier.
Finally, if you're still not convinced about the importance of flat hierarchies and the reduced significance of file names, consider how often you actually need to search for a file. For me, it's only two or three times a month, which isn't a significant burden. I can quickly browse through a few files or use full-text search to find what I need.
Think about the effort versus benefit ratio, and see if this approach works for you.
Happy organising!
If you prefer to watch rather than read, here is the video: